
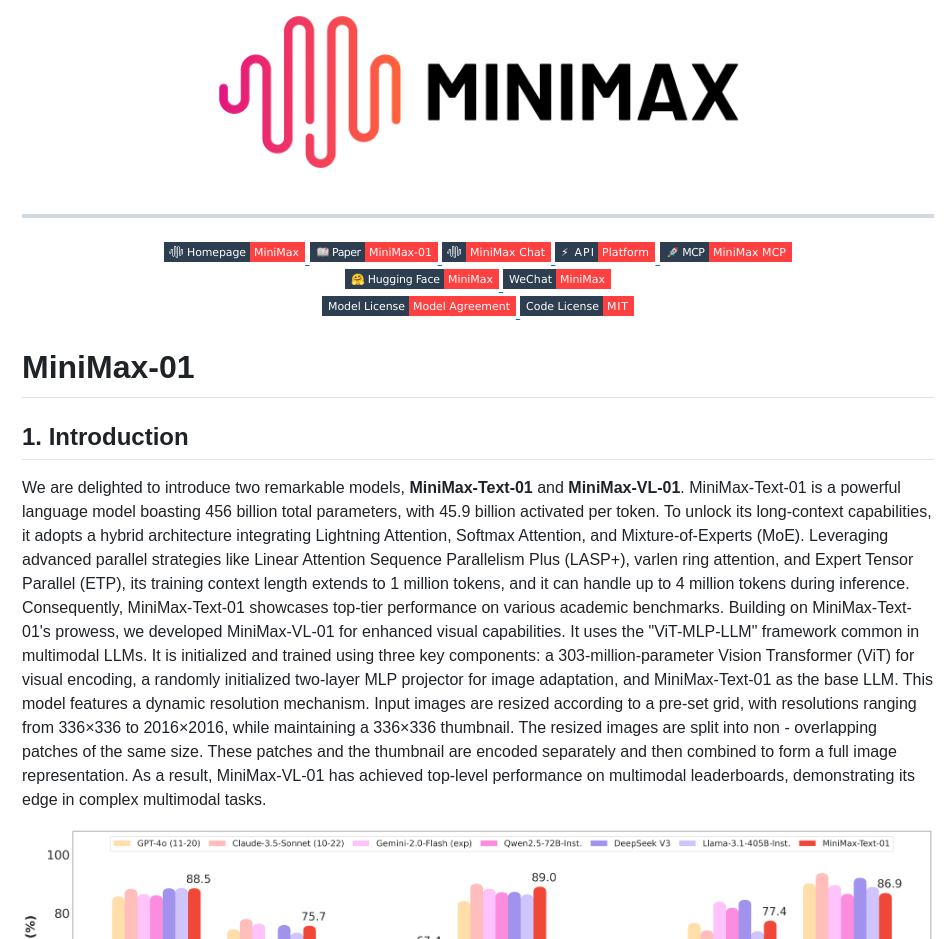
LLaVA-VL/LLaVA-NeXT
open large multimodal models for vision and language tasks

View on index · View in 3D Map
Related repos
- unified multimodal model for both understanding and generating images and text
- Multimodal foundation models for video understanding

- Mixture-of-Experts vision-language model

- multimodal model for text-to-image, image editing, and in-context generation
- Toolkit for fine-tuning and training large language and vision models

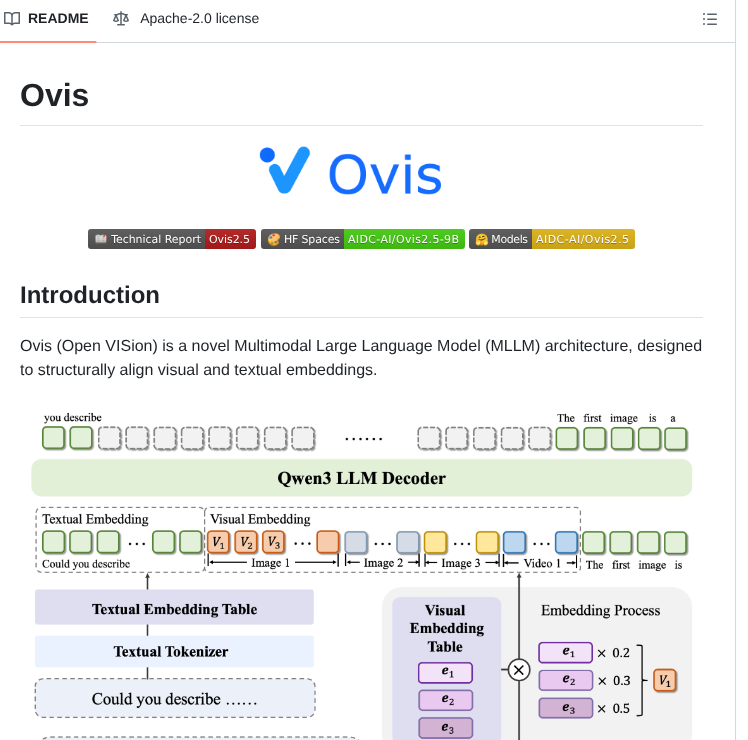
- Multimodal large language model that aligns visual and textual embeddings
- Code and tutorials for building large language models from scratch in PyTorch
- open-source language and vision models with huge context window and hybrid attention
- End-to-end multimodal LLM for any-to-any I/O
- Survey of unified multimodal models
