Towards Resistant Audio Adversarial Examples
Towards Resistant Audio Adversarial Examples
tom.doerr@tum.de; karla.markert@aisec.fraunhofer.de; nicolas.mueller@aisec.fraunhofer.de; konstantin.boettinger@aisec.fraunhofer.de
*Both authors contributed equally to this research.
Adversarial examples tremendously threaten the availability and integrity of machine learning-based systems. While the feasibility of such attacks has been observed first in the domain of image processing, recent research shows that speech recognition is also susceptible to adversarial attacks. However, reliably bridging the air gap (i.e., making the adversarial examples work when recorded via a microphone) has so far eluded researchers. We find that due to flaws in the generation process, state-of-the-art adversarial example generation methods cause overfitting because of the binning operation in the target speech recognition system (e.g., Mozilla Deepspeech). We devise an approach to mitigate this flaw and find that our method improves generation of adversarial examples with varying offsets. We confirm the significant improvement with our approach by empirical comparison of the edit distance in a realistic over-the-air setting. Our approach states a significant step towards over-the-air attacks. We publish the code and an applicable implementation of our approach.
Note that this is a limited PDF or print version; animated and interactive figures are disabled. For the full version of this article, please visit https://andrewgyork.github.io/publication_template
Examples
Without Offset Training
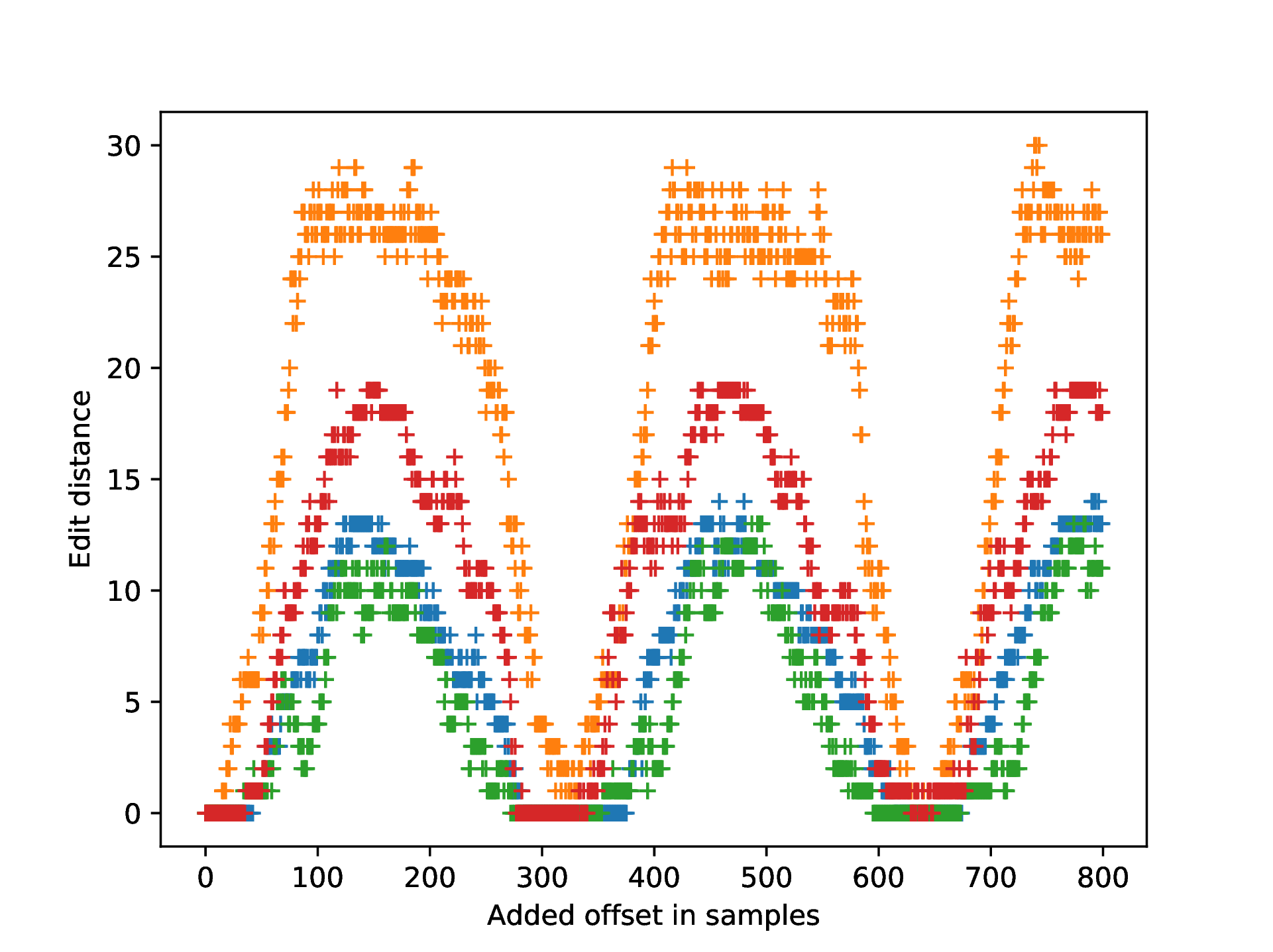
With Offset Training