
fla-org/flash-linear-attention
Efficient Triton-based linear attention kernels for PyTorch and multiple hardware platforms
View on index · View in 3D Map
Related repos
- fast attention algorithm for transformers, boosts speed and memory efficiency
- Sparse attention for long video generation
- Model with sparse attention for long-context scenarios

- PyTorch models for high-res vision tasks using self-supervised learning
- open-source language and vision models with huge context window and hybrid attention
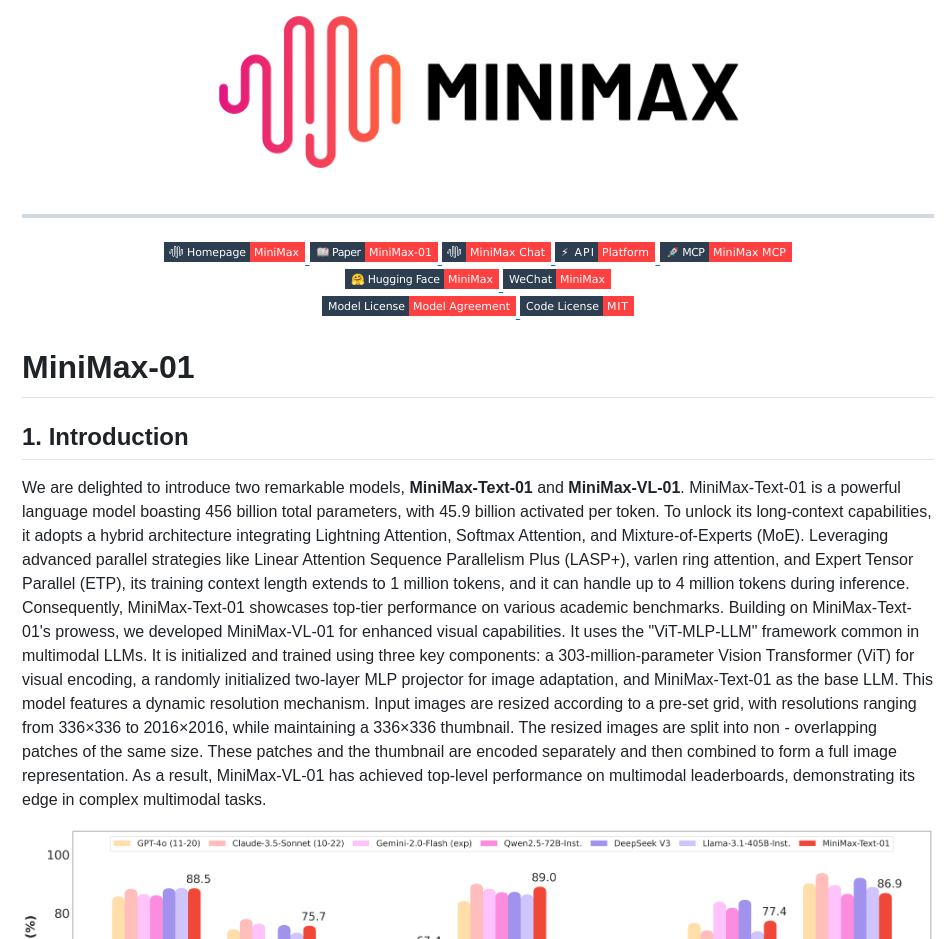
- Toolkit for fine-tuning and training large language and vision models

- C++ library for machine learning tasks and research

- Unified benchmark for scene text detection and recognition
- PyTorch-based framework for deep learning in healthcare imaging

- Unified platform for training and evaluating multiple optical flow models using PyTorch Lightning
