
lyogavin/airllm
Run 70B LLMs on a 4GB GPU with layer-wise inference and memory optimization, quantization optional
View on index · View in 3D Map
Related repos
- run local LLMs fast on consumer GPUs with flexible quantization
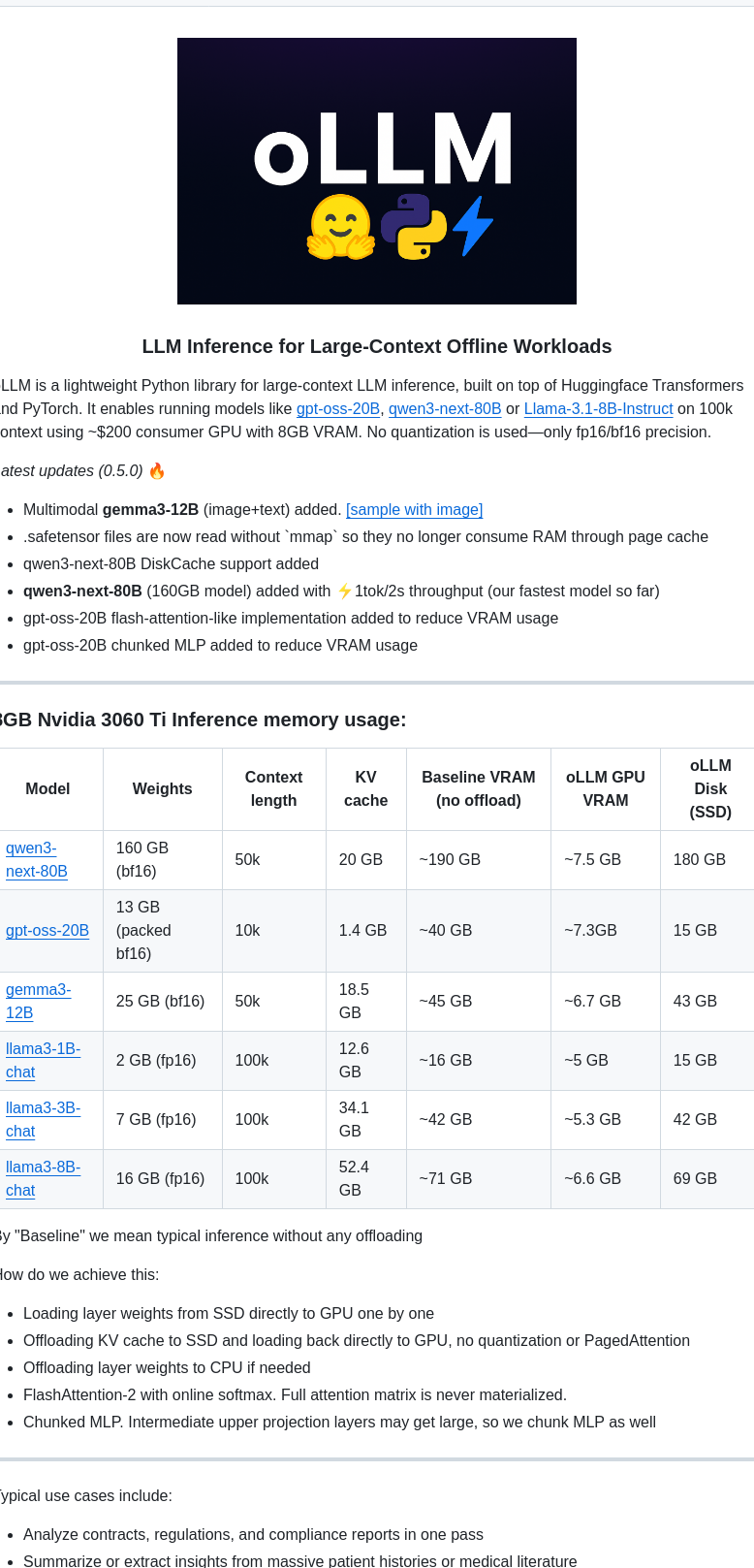
- Run huge LLMs with 100k context on an 8GB GPU using SSD offload, no quantization
- 1-bit LLM inference on CPUs and GPUs with BitNet

- Runs LLMs on AMD NPUs
- framework for fast, resource-efficient LLM inference on local hardware
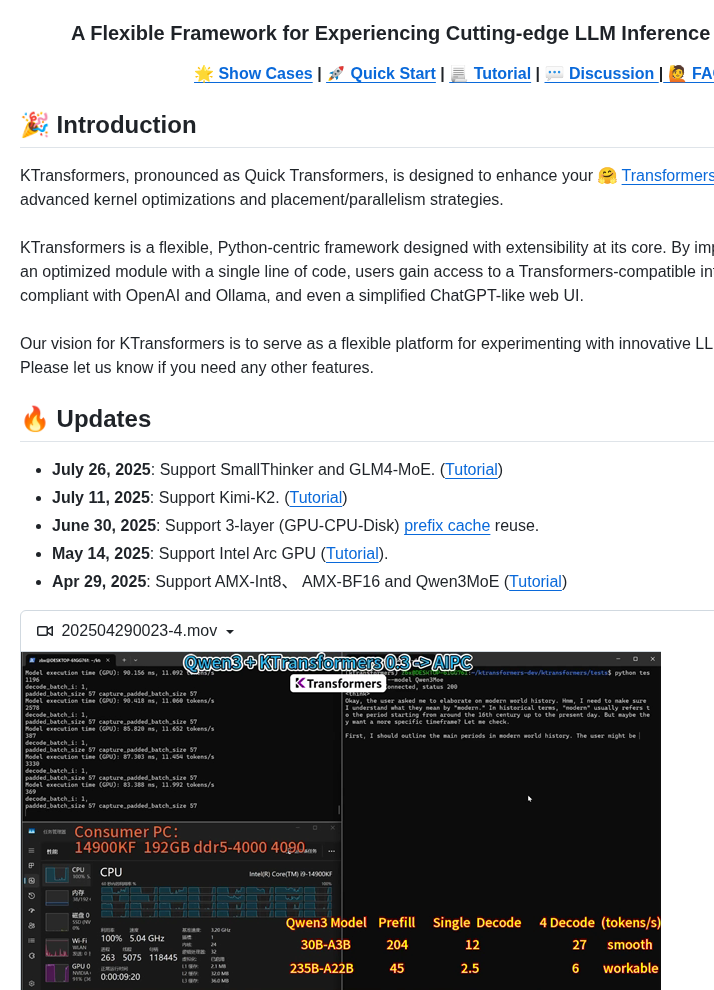
- Self-hosted GPU video compressor targeting file sizes
- Fine-tunes LLMs on Apple silicon
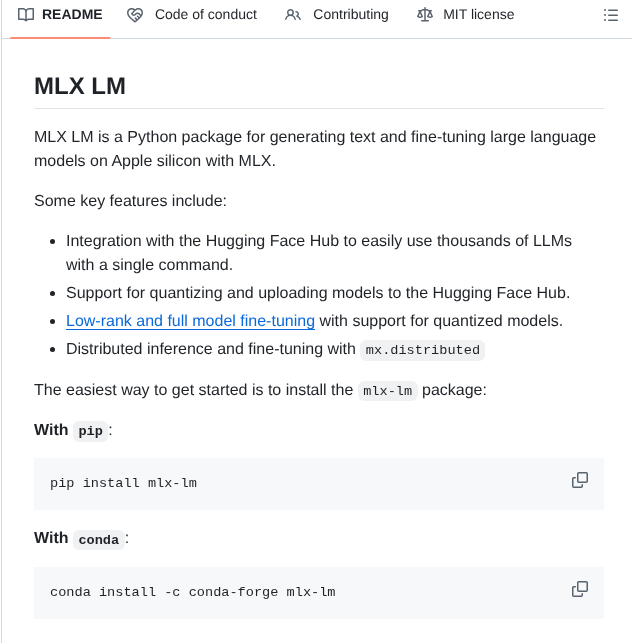
- run large language models on any device
- open source video generation for low VRAM GPUs

- plug and play memory layer for LLMs
