DevTechJr/turboquant-gpu
KV cache compression for LLM inference with 5.02x ratio
View on index · View in 3D Map
Related repos
- run local LLMs fast on consumer GPUs with flexible quantization
- GPU-optimized library for training massive transformer models at scale
- framework for fast, resource-efficient LLM inference on local hardware
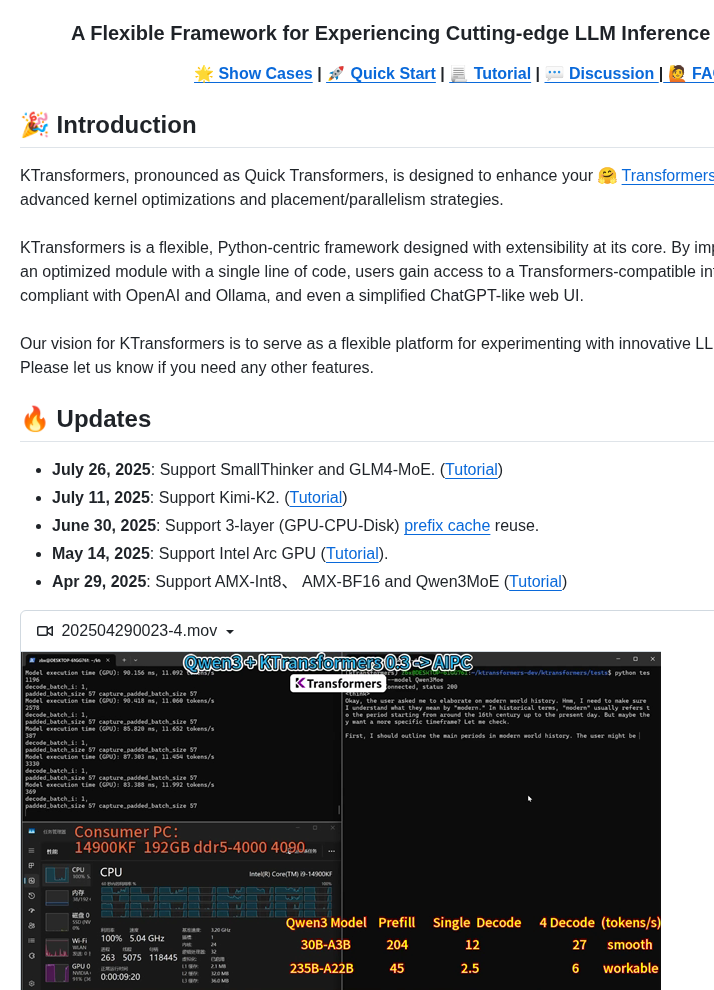
- Nanosecond resolution CPU GPU profiler
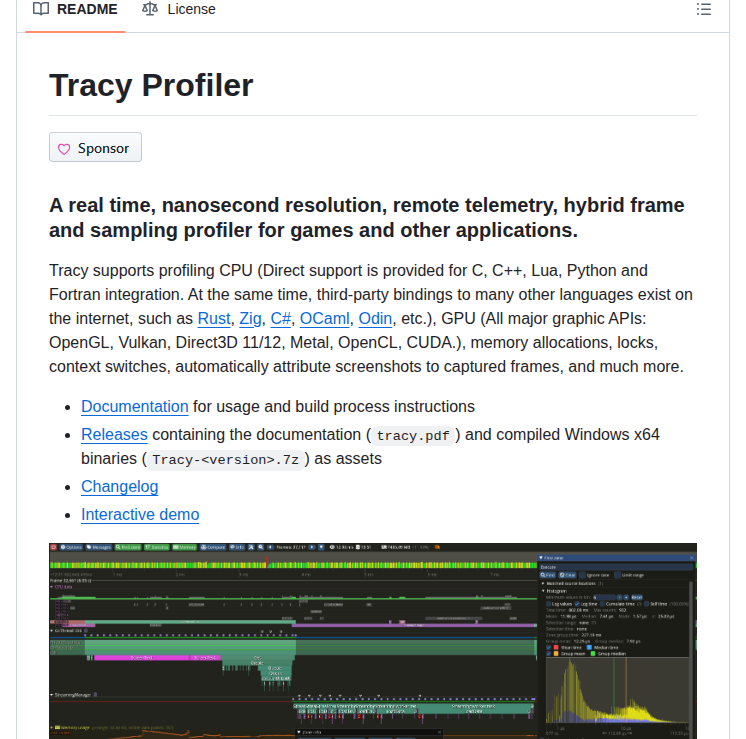
- Self-hosted GPU video compressor targeting file sizes
- Matches LLM models to hardware specifications

- Runs LLMs on Ryzen NPUs without GPUs

- 1-bit LLM inference on CPUs and GPUs with BitNet

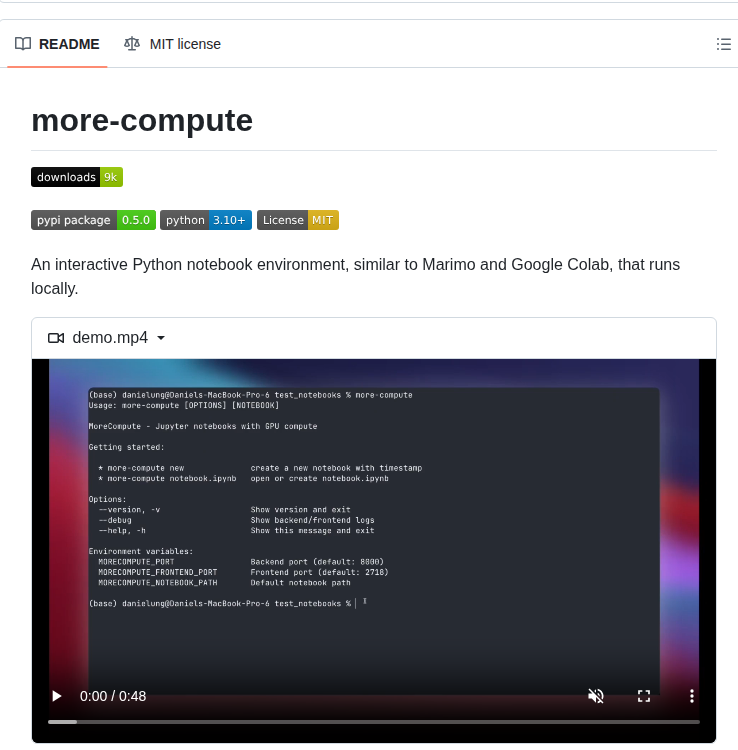
- Python notebook environment with GPU compute
- Tool for testing LLM vulnerabilities